


AI Ship Weekly | 04-11 April 2023
Google ViT-22B, Androphic, Meta SAM and more...

Click for the Turkish version of this newsletter (bu bültenin Türkçe’si için tıkla).
Hello everyone from a new Tuesday!
In the fourth issue of AI Ship, I am again sharing the latest news from the AI world. Without further ado, let's take a look at the hottest developments together...
Newsletter Content:
1) Google ViT-22B
2) Androphic
3) Midjourney New Features
4) Meta SAM

Highlights of the Week
1) Google ViT-22B
Google recently announced a newly developed artificial intelligence model. This model consists of exactly 22 billion parameters. This model, which enables the recognition of images, contains approximately 6 times more parameters than the previous model.
The main purpose of the model can be summarized as computers achieving artificial vision close to human vision.
You can find more detailed information here.
2) Androphic
In recent months, Anthropics, founded by former OpenAI employees, in which Google invested 300 million dollars, aims to surpass OpenAI with an investment of 5 billion dollars.
Anthropics plans to develop a model 10 times more powerful than the current most powerful AI model. This new model is described as a "next-generation algorithm" that enables AI to learn on its own.
Even more important is this statement:
"Such models will be able to start automating large parts of the economy. We believe that the companies that develop the best models in 2025/26 will be too far ahead to be caught by anyone in future cycles."
In other words, unlike GPT-4, this model will be self-learning... Since this sentence alone would be the subject of a different article, we will skip this news for now, and we will come back here when the details about Androphic are fully clarified and shared with the public:)
3) Midjourney New Features
With its 5th version, Midjourney amazed everyone with what it could do. Now it has made a sound again with its newly announced features. Here are those features;
a) /describe: With this command, it will describe the image you uploaded for you, that is, it will prompt. All 4 of them at once. And with these prompts you will be able to reproduce the same style image. Here is an example for full understanding;
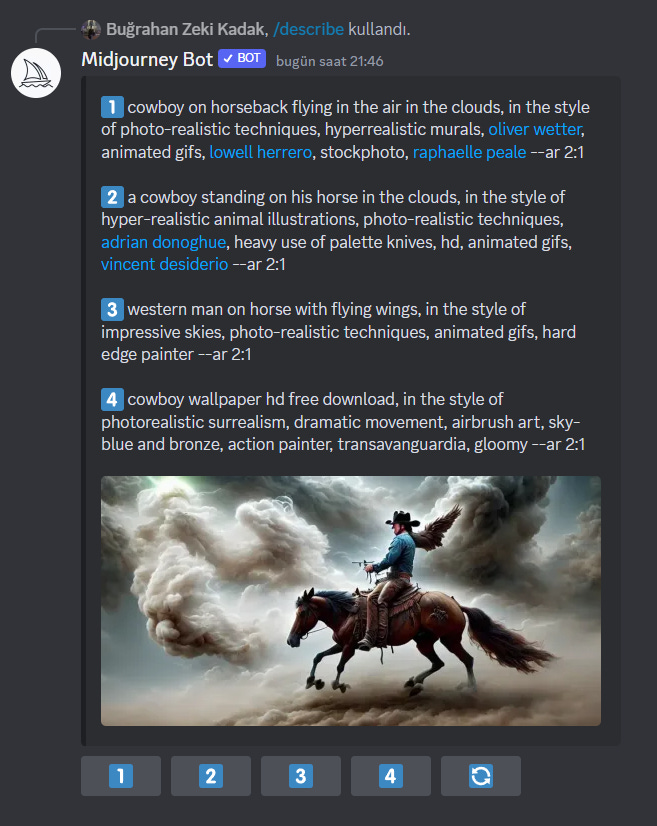
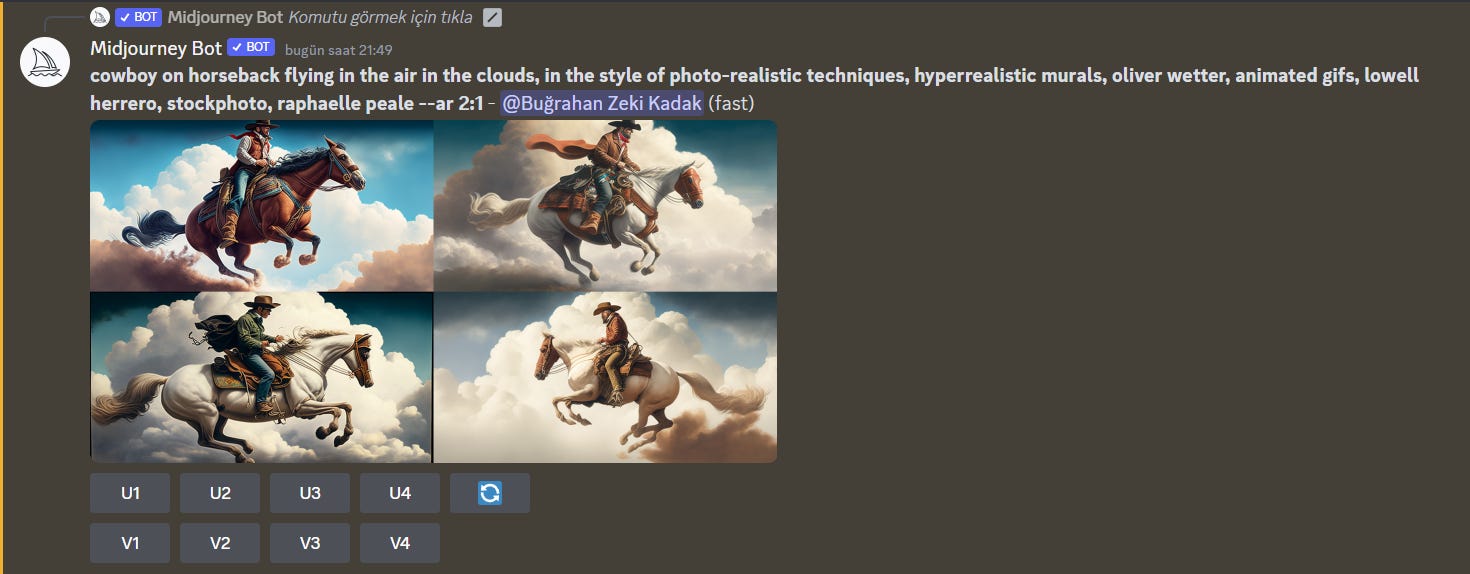
I sent this image I generated from Stockimg AI with the /describe command and it gave me 4 prompts describing this image as output. Really amazing! Now let me share the image I produced in midjoruney with the 1st prompt;
b) --repeat: With the --repeat [count] parameter, you can generate as many images as you want. Until now, as you have seen above, you could generate 4 images. For example, if you add --repeat 3, you will be able to generate 3 2x2 images (that's 12 images in total).
c) permutations: let me explain this feature with a single example. For example, you want to generate two cars, black and white. For this, you would have to produce with two separate commands, /imagine black car and /imagine white car. With this feature, you can get two different results at the same time by typing /imagine {black, white} car.
4) Meta SAM
Last week, Facebook, now Meta, open-sourced a revolutionary model called SAM (Segment Anything Model). This model has the ability to segment objects in any photo or video with a single click. Meta also announced SA-1B, a dataset 400 times larger than existing segmentation datasets. Meta's goal is that this work will accelerate research in computer vision and help create entirely new application areas.
I tried it on the image you see just below and the results are really great. It can easily distinguish all objects in an image.

That's all I have for you this week. I hope you enjoyed it. I won't be able to talk much about Thesus' ship this week because I'm busy building the mobile app for Stockimg AI. I will let you know when it is released in the store for you to download. See you in other ports, goodbye for now, and don't capsize!